
AWS의 컨테이너 서비스를 통해서 AWS는 서버, 인프라, OS, 컨테이너 런타임 등의 환경을 제공하고, 사용자는 컨테이너 config와 애플리케이션 등에 책임을 가져가며 컨테이너 애플리케이션을 위한 인프라 서비스를 제공받을 수 있다.
Elastic Container Service
컨테이너 애플리케이션이 필수가 된 요즘 쿠버네티스가 컨테이너 오케스트레이션 플랫폼으로 많은 선택을 받고 있다. AWS에서도 이를 지원하는 Elastic Kubernetes Service(EKS)가 있지만, 완전 관리형 컨테이너 오케스트레이션 서비스인 Elastic Container Service(ECS)도 존재한다. ECS를 사용하면 후에 컨테이너 오케스트레이션 플랫폼을 교체할 때 마이그레이션이 힘들 수도 있겠지만, AWS ECS를 장기간 사용할 것이라면 완전 관리형으로써 얻을 수 있는 편안함이 많다.
ECS로 컨테이너를 배포하기 위한 대상 용량은 3가지 옵션이 있다. AWS가 자체적으로 인프라를 관리하는 Fargate, 사용자가 용량을 관리할 EC2 인스턴스, 그리고 온프레미스 환경의 서버나 가상머신 등 외부 인스턴스 옵션이 있다. ECS의 핵심 요소들인 클러스터, 서비스, 태스크, 계정 설정 등은 공통적인 서비스 범위이지만 용량 옵션 별로 다른 점이 상당하기 때문에 우선적으로 핵심적인 구성 요소들과 Fargate 유형을 살펴보려한다.
Features
ECS는 크게 애플리케이션이 실행되는 인프라인 클러스터, 태스크 인스턴스를 관리하는 서비스, 미리 정의된 컨테이너 설정 등인 task definition 기반으로 만들어지는 컨테이너 애플리케이션인 태스크가 존재한다.

서버리스인 Fargate 용량 유형의 구조를 간략하게 그려보았다. 각 영역 별로 엑세스 제어나 권한을 제어할 IAM 정책 혹은 역할 등을 부여할 수 있다.
클러스터
ECS클러스터는 실제 애플리케이션인 태스크나 서비스 등을 묶어 놓은 논리적 그룹이고, 클러스터의 태스크나 서비스 등이 실제로 동작할 인프라 용량 등의 리소스가 포함된 환경이다. 클러스터는 region 별로 존재할 수 있으며, 기본 옵션으로 서버리스인 Fargate 유형이 선택된다.
AWS에서 관리하는 KMS 키를 선택해 인스턴스에 연결된 EBS나 EFS에 저장되는 리소스에 대한 암호화도 가능하다.
클러스터 모니터링
모니터링 기본 유형을 선택하면 서비스 단위의 기본적인 CPU 사용량이나 메모리 등에 대한 지표와 태스크 단위의 네트워크RxTx 등에 대한 지표를 확인할 수 있다.

약간의 추가적인 금액을 매달 지불한다면 클러스터 레벨부터 컨테이너 인스턴스 레벨까지의 모니터링을 할 수 있는 Container Insight를 CloudWatch에서 활성화할 수 있다.

2024년부턴 ECS에 Container Insights with enhanced observability를 지원한다.
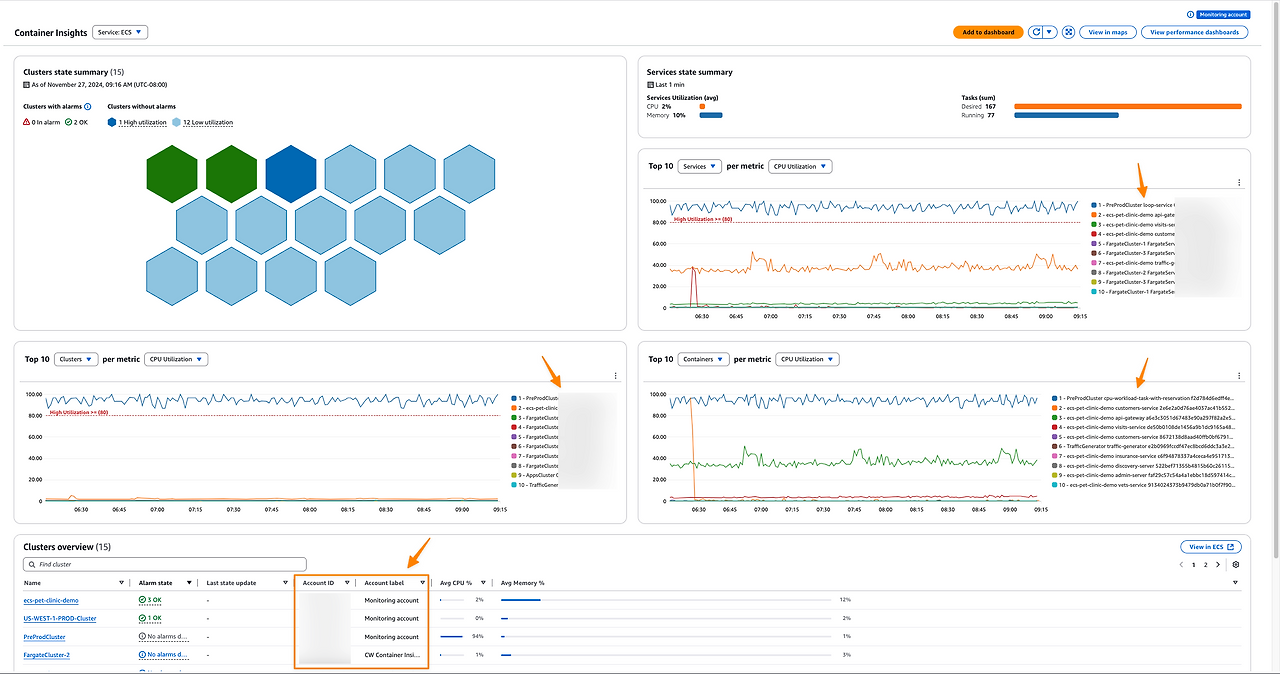
AWS X-Ray를 이용한 분산 시스템의 분산 추적, 고급 메트릭, 애플리케이션 수준의 로깅 분석이나 쿼리 등 더욱 다양하고 자세한 모니터링이 가능하다.
인프라 용량을 조절하는 클러스터에는 Capacity Provider를 통해 서비스나 태스크에 용량을 공급한다. Fargate 유형은 기본적으로 `FARGATE`와 `FARGATE_SPOT`이 등록된다.

서비스
클러스터 상에서 컨테이너 애플리케이션을 배포하기 위해선 태스크를 독립적으로 실행하거나, 서비스를 통해서 태스크를 실행할 수 있다. ECS 서비스를 사용하면 클러스터에서 중지되는 태스크 발생 시 인스턴스를 교체하는 등 지정된 수의 인스턴스 유지 관리를 할 수 있다. ECS 서비스는 지정된 수만큼의 태스크를 운용하지만, ECS 서비스 자체는 버전 관리와 가용성이 좋은 stateless 애플리케이션이다.

ECS 서비스 스케쥴러가 ECS 서비스 인스턴스 유지 관리를 행하게 되는데, 그에 대한 기준으로 용량공급자를 선택할 수도 있고, 용량공급자가 없는 시작 유형을 선택할 수 있다. 용량공급자를 선택하게 되면 용량공급자 전략에도 맞춰 인스턴스를 늘리거나 줄이게 되고, 그렇지 않으면 `desiredCount`에만 맞춰서 태스크를 유지한다.

서비스 스케쥴러가 실행시킬 태스크의 정의를 선택해야하고, Fargate 시작 유형은 기본적으로 서비스 유형이 `Replica`이다. `Daemon`유형은 클러스터에 등록된 인스턴스에 모두 태스크가 실행되는 것이지만 `Replica`유형은 클러스터에 등록된 인스턴스 수와 상관없이 원하는 수만큼의 태스크만이 여러 가용영역에 밸런스 있게 배포되는 것이다. `Replica`는 실제 서비스와 관계있는 유형이고, 그러한 인터넷 서비스 유형이 고려대상이 아닐 때 `Daemon`유형을 고려하면 된다. 예를 들면, 로그 수집이나 모니터링 등에 대한 시스템 레벨 에이전트가 필요할 때다.
AZ Rebalancing
AZ Rebalancing은 서비스된 태스크들이 불균형하게 배포되었다면, 다시 균형에 맞게 배포하는 것이다.
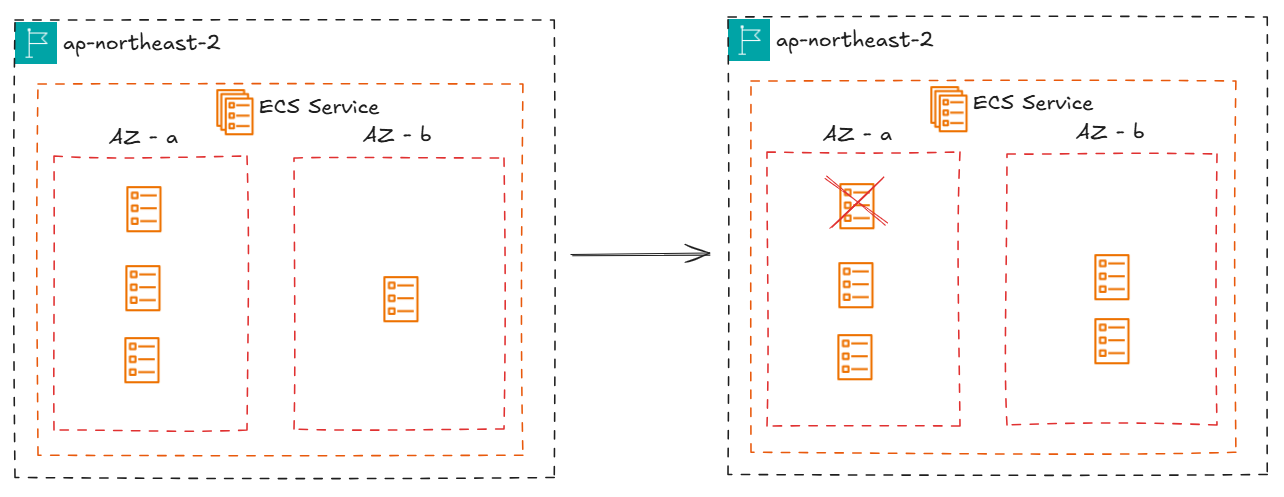
리밸런싱이 시작되면 태스크가 가장 적은 AZ에서 태스크를 실행하고, 태스크가 가장 많은 AZ에서 태스크를 종료하는, 아주 단순한 리밸런싱이다.
Rolling Update
ECS 서비스를 사용하면 롤링 방식과 블루/그린 배포 방식으로 배포 옵션을 선택할 수 있다.

기본적으로는 롤링 방식이 ECS 서비스의 기본 배포 방식으로, 컨테이너의 새로운 버전으로 배포 업데이트 시 순차적인 업데이트 배포 방식이다.
예를 들어, `desiredCount`가 6인 ECS 서비스가 태스크 인스턴스를 유지 관리하고 있다고 가정해보자.

롤링 방식의 `minimum running tasks %`는 동작해야할 최소한의 태스크 비율이고, `maximum running tasks %`는 동작할 수 있는 최대한의 태스크 비율로 각각 ECS 서비스 파라미터는 `minimumHealthyPercent`와 `maximumPercent`이다. `minimumHealthyPercent`는 기본값으로 100%이며, `maximumPercent`는 200%이다. 즉, 새로운 버전의 배포가 발생하면 기존 태스크들은 모두 동작하는 상태에서 새로운 버전의 태스크들이 별도로 실행된 뒤, health check를 통과하는 태스크들만 교체가 된다.

만약 `minimumHealthyPercent`가 50%로 6개 중 3개의 태스크만 정상적으로 동작해야하고, `maximumPercent`가 100%로 최대 6개의 태스크만 동작시킬 수 있다면, 우선적으로 3개의 태스크를 종료시키고 3개의 새로운 태스크를 실행해서 부분 업데이트를 수행한다.

먼저 갱신된 3개의 새로운 버전의 컨테이너가 정상적으로 동작할 것이고, 남은 3개의 태스크에 대한 배포가 진행된다.
이와 같이 `minimumHealthyPercent`와 `maximumPercent` 수치를 관리해서 롤링 방식의 배포 속도와 가용성을 조절이 가능하고, 만약 배포에 실패할 시 이전 버전으로 롤백하는 옵션도 활성화 할 수 있다.
Blue/Green Deployment
블루/그린 배포 방식은 일반적으로 하나의 스탠바이를 대기시켜 곧바로 배포하거나 혹은 롤백을 용이하게 할 수 있는 배포 방식이지만, 기본적으로 스탠바이를 대기시키기 때문에 리소스가 두배로 발생하는 배포 방식이다. AWS ECS 서비스의 배포 방식으로 블루/그린 배포 방식을 지원하는데, 이는 AWS CodeDeploy 서비스를 사용해서 100%의 스탠바이가 아닌 카나리 방식의 배포 방식을 적용시킬 수도 있다.
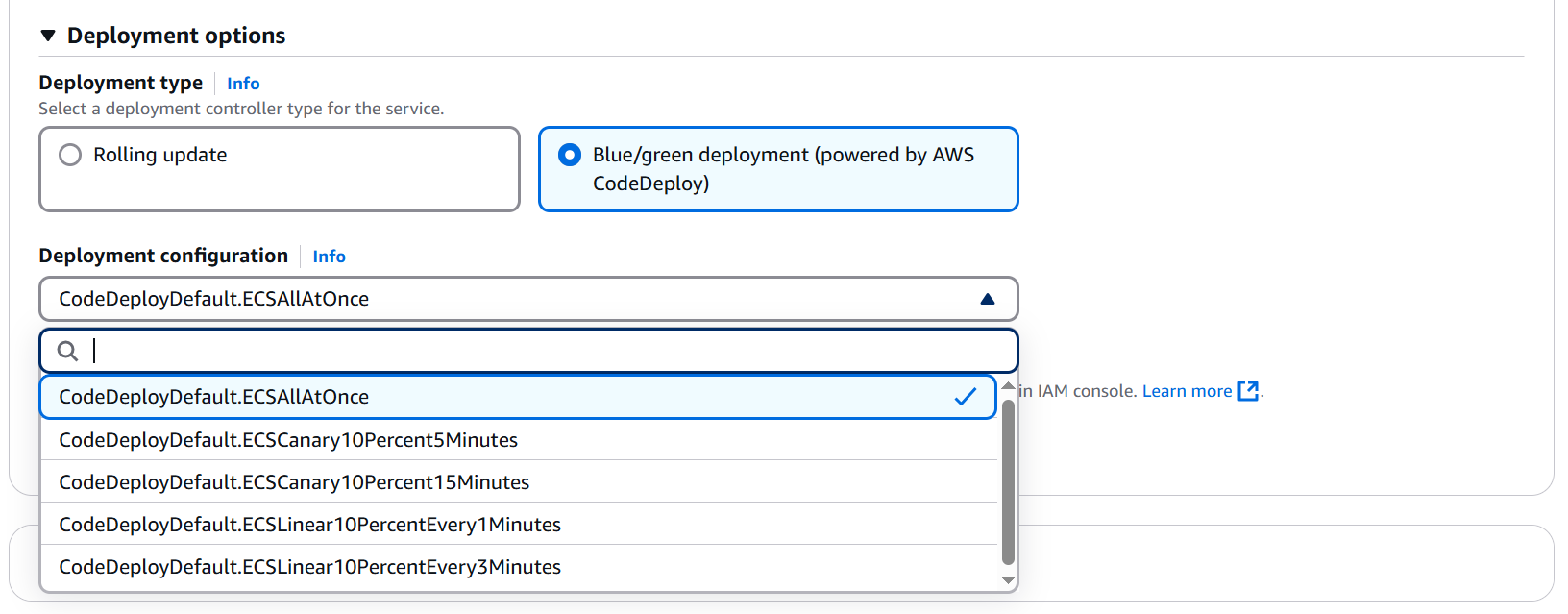
`AllAtOnce`란 한 번에 모든 리소스가 교체되는 것이고, 우선적인 10% + 이후 90% 배포에 대한 카나리 방식과, 일정 시간마다 10%씩 배포가 되는 linear 방식을 블루/그린 배포 방식으로 선택할 수 있다.
블루/그린 배포 방식을 지원하기 위해선 ECS 서비스가 ELB에 연결되어 있어야한다. 블루/그린 환경은 ELB가 가리키는 타겟 그룹이 된다. ECS 서비스 태스크에 대한 권한이 있는 IAM 역할을 가진 CodeDeploy 서비스에서 그린 타겟 그룹에 배포를 성공하면 ELB가 그린 타겟 그룹으로 라우팅하며 블루/그린 배포가 진행된다.
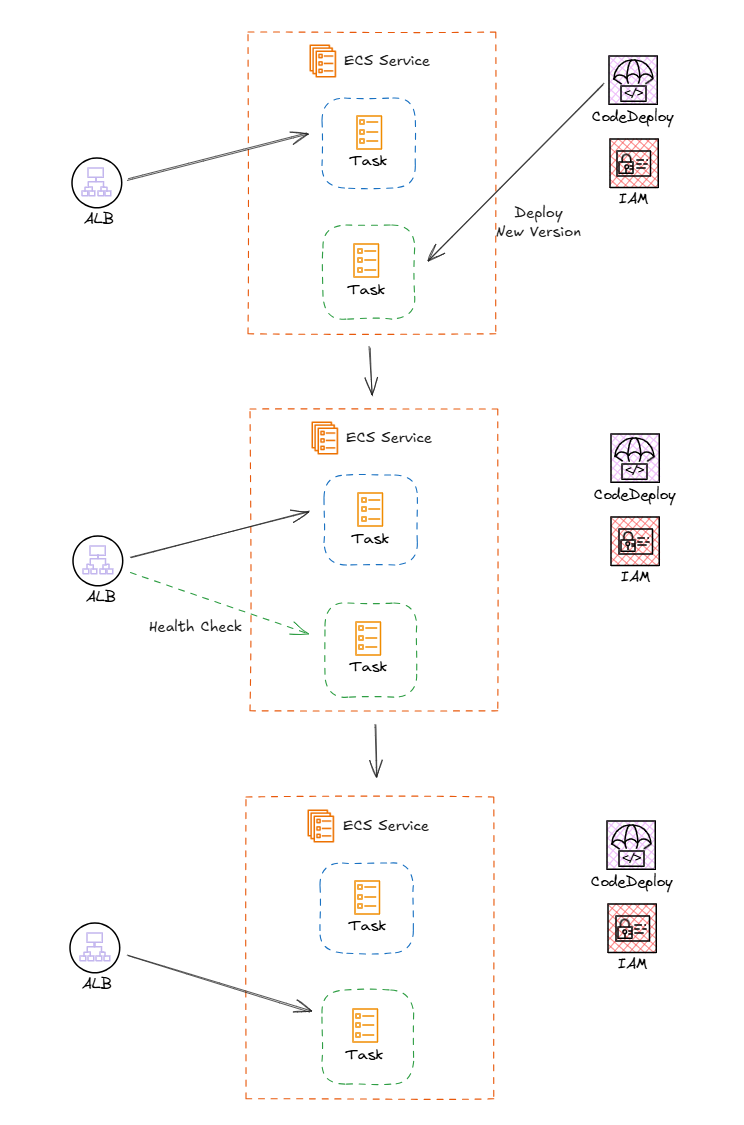
네트워크

ECS 서비스는 클러스터의 region에 자동으로 포함되고, 구체적인 VPC와 서브넷 등의 네트워크 대역을 ECS 서비스에서 설정한다. ECS 서비스를 통해 생성된 인스턴스들은 해당 네트워크에 해당되며, 인스턴스들의 보안그룹 또한 설정된 보안그룹을 할당받게 된다.
가장 아래의 Public IP는 컨테이너 네트워크 형식이 `awsvpc`일 경우에만 가능하다. `awsvpc`일 경우 컨테이너 네트워크 내의 컨테이너 인스턴스는 모두 ENI(Elastic Network Interface)를 할당받게 된다. 그럼 해당 ENI에 public IP를 할당하는 것이 가능하기 때문에 해당 옵션을 활성화 할 수 있다. 하지만, 기본 도커 네트워크인 `bridge`나 `host`를 태스크의 네트워크 모드로 설정한다면, 외부의 네트워크가 아닌 컨테이너 런타임 내부의 네트워크이기 때문에 컨테이너는 호스트의 NAT에 따르게 된다. 그렇기 때문에 해당 옵션이 켜져있더라도, 활성화되지 못한다.
하지만 AWS에서 권장하는 네트워크 best practice는 항상 인스턴스를 private subnet에 위치시키고, 외부 연결은 NAT 게이트웨이 등을 통해서 하는 것이기 때문에 public IP는 별로 좋지 못한 옵션이다.
Load Balancing
ECS 서비스가 관리하는 인스턴스를 ELB와 연동시킬 수 있다. 주로 ALB와 연결되며, NLB나 GWLB 또한 연동이 가능하다. 고성능을 위해서 NLB가 연동되는 경우도 있으며, NLB의 경우 PrivateLink 사용이 가능하니 VPC간의 연결을 Interface Endpoint를 생성해 private하게 사용할 수도 있다.
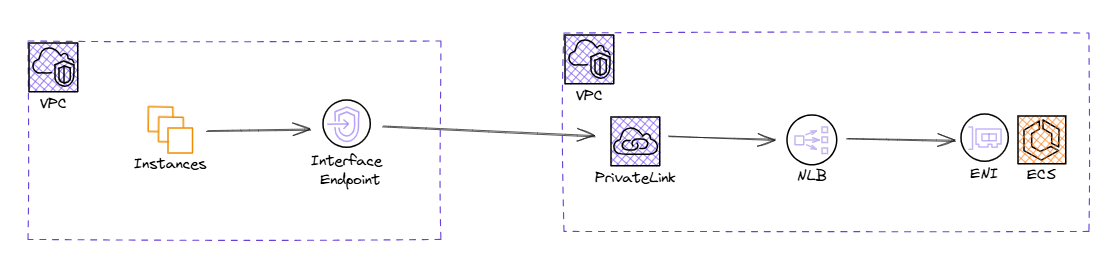
이러한 PrivateLink를 통한 연결을 위해선 ECS 서비스 태스크의 네트워크 모드는 `awsvpc`모드로 설정되어 컨테이너 인스턴스에 ENI가 할당되어야 해당 인스턴스가 NLB로부터 라우팅 될 수 있다.
Service Auto Scaling
ECS 서비스는 목표하는 태스크 수가 `desiredCount`로 존재한다. 해당 태스크에 대한, 즉, 컨테이너에 대한 오토스케일링을 담당하는 것이 Service Auto Scaling이다. Application Auto Scaling이라고도 한다.

기존의 ASG와의 차이점은, EC2에 대한 ASG가 아니라 컨테이너 레벨의 태스크에 대한 오토스케일링을 수행한다는 것이다. Service Auto Scaling을 통해 태스크의 오토스케일링이 진행된다고 해도 EC2 인스턴스가 부족하면 인프라가 부족해서 실제로 배포할 물리적인 인프라 용량이 부족하게된다.

Fargate 시작 유형에선 이러한 인프라 용량 관리를 AWS가 직접 담당하니 걱정할 것은 비용 밖에 없다.
Volume
Fargate 유형의 ECS 서비스는 태스크 인스턴스 생성 시 기본적으로 임시의 볼륨을 제공 받지만, 태스크가 종료되면 볼륨 또한 소멸된다. 영구적인 볼륨 사용을 위해 태스크 런칭 시 EBS 볼륨을 설정할 수도 있다. 태스크 정의에서 `configuredAtLaunch`를 `true`로 설정하면 서비스가 태스크 인스턴스를 실행할 때 마다 설정할 볼륨에 대해서 정의할 수 있다. 서비스에선 EBS 볼륨만 설정할 수 있지만, 태스크를 직접 정의할 땐 EFS, FSx for Windows, 도커 볼륨 등에 대한 설정을 할 수 있다.
태스크
태스크는 ECS 클러스터 상에서 배포되는 애플리케이션에 대한 파라미터들과 애플리케이션의 하나 이상의 컨테이너에 대한 설정을 기반으로 실행하는 작업이다. 이러한 작업에 대한 정의를 먼저 만들어 놓은 것이 task definition, 태스크 정의이다. 태스크 정의와 태스크는 클래스와 인스턴스라고 생각하면된다. 태스크 정의는 태스크에 대한 설계를 JSON으로 정리해둔 것이고, 이를 인스턴스화해서 클러스터 상에서 실체화된 프로그램이 태스크이다.

컨테이너의 CPU는 1/1024 vCPU 단위이며, 우리가 흔히 아는 1 vCPU는 1024CPU로 설정하면 된다. 메모리의 단위는 mb이다.
태스크 정의 템플릿
태스크 정의에는 다양한 값이 들어갈 수 있고, 필수인 값은 그리 많지 않다. 템플릿은 아래와 같다.
{
"family": "",
"runtimePlatform": {"operatingSystemFamily": ""},
"taskRoleArn": "",
"executionRoleArn": "",
"networkMode": "awsvpc",
"platformFamily": "",
"containerDefinitions": [
{
"name": "",
"image": "",
"repositoryCredentials": {"credentialsParameter": ""},
"cpu": 0,
"memory": 0,
"memoryReservation": 0,
"links": [""],
"portMappings": [
{
"containerPort": 0,
"hostPort": 0,
"protocol": "tcp"
}
],
"essential": true,
"entryPoint": [""],
"command": [""],
"environment": [
{
"name": "",
"value": ""
}
],
"environmentFiles": [
{
"value": "",
"type": "s3"
}
],
"mountPoints": [
{
"sourceVolume": "",
"containerPath": "",
"readOnly": true
}
],
"volumesFrom": [
{
"sourceContainer": "",
"readOnly": true
}
],
"linuxParameters": {
"capabilities": {
"add": [""],
"drop": [""]
},
"devices": [
{
"hostPath": "",
"containerPath": "",
"permissions": ["read"]
}
],
"initProcessEnabled": true,
"sharedMemorySize": 0,
"tmpfs": [
{
"containerPath": "",
"size": 0,
"mountOptions": [""]
}
],
"maxSwap": 0,
"swappiness": 0
},
"secrets": [
{
"name": "",
"valueFrom": ""
}
],
"dependsOn": [
{
"containerName": "",
"condition": "HEALTHY"
}
],
"startTimeout": 0,
"stopTimeout": 0,
"hostname": "",
"user": "",
"workingDirectory": "",
"disableNetworking": true,
"privileged": true,
"readonlyRootFilesystem": true,
"dnsServers": [""],
"dnsSearchDomains": [""],
"extraHosts": [
{
"hostname": "",
"ipAddress": ""
}
],
"dockerSecurityOptions": [""],
"interactive": true,
"pseudoTerminal": true,
"dockerLabels": {"KeyName": ""},
"ulimits": [
{
"name": "msgqueue",
"softLimit": 0,
"hardLimit": 0
}
],
"logConfiguration": {
"logDriver": "awslogs",
"options": {"KeyName": ""},
"secretOptions": [
{
"name": "",
"valueFrom": ""
}
]
},
"healthCheck": {
"command": [""],
"interval": 0,
"timeout": 0,
"retries": 0,
"startPeriod": 0
},
"systemControls": [
{
"namespace": "",
"value": ""
}
],
"resourceRequirements": [
{
"value": "",
"type": "GPU"
}
],
"firelensConfiguration": {
"type": "fluentd",
"options": {"KeyName": ""}
}
}
],
"volumes": [
{
"name": "",
"host": {"sourcePath": ""},
"configuredAtLaunch":true,
"dockerVolumeConfiguration": {
"scope": "task",
"autoprovision": true,
"driver": "",
"driverOpts": {"KeyName": ""},
"labels": {"KeyName": ""}
},
"efsVolumeConfiguration": {
"fileSystemId": "",
"rootDirectory": "",
"transitEncryption": "ENABLED",
"transitEncryptionPort": 0,
"authorizationConfig": {
"accessPointId": "",
"iam": "ENABLED"
}
}
}
],
"requiresCompatibilities": ["FARGATE"],
"cpu": "",
"memory": "",
"tags": [
{
"key": "",
"value": ""
}
],
"ephemeralStorage": {"sizeInGiB": 0},
"pidMode": "task",
"ipcMode": "none",
"proxyConfiguration": {
"type": "APPMESH",
"containerName": "",
"properties": [
{
"name": "",
"value": ""
}
]
},
"inferenceAccelerators": [
{
"deviceName": "",
"deviceType": ""
}
]
}
Volume
기본적으로 Fargate 유형의 태스크 인스턴스는 임시 스토리지를 부여받는다. 플랫폼 버전에 따라 Linux 1.3.0 이하 버전의 플랫폼은 10GB의 도커 스토리지를 받고, 1.4.0 이상의 플랫폼이라면 최소 20GB 이상, 최대 200GB의 임시 스토리지를 할당할 수 있다.
태스크 정의에서 볼륨에 대한 정의 또한 작성할 수 있다. Fargate 유형에서 지원되는 볼륨 유형은 EBS와 EFS가 있으며, 호스트의 임시 스토리지 또한 bind mount를 통해 여러 컨테이너가 공유할 수 있다.
FROM public.ecr.aws/amazonlinux/amazonlinux:latest
RUN yum install -y shadow-utils && yum clean all
RUN useradd node
RUN mkdir -p /var/log/exported && chown node:node /var/log/exported
USER node
RUN touch /var/log/exported/examplefile
VOLUME ["/var/log/exported"]위와 같이 Dockerfile을 정의하고, `VOLUME`에 적힌 디렉토리를 그대로 컨테이너 경로에 적용한다면,
{
"family": "mytaskdef",
...
"volumes": [
{
"name": "application_logs"
}
],
"containerDefinitions": [
{
"name": "application1",
"image": "my-repo/application",
"cpu": 100,
"memory": 100,
"essential": true,
"mountPoints": [
{
"sourceVolume": "application_logs",
"containerPath": "/var/log/exported"
}
]
},
{
"name": "application2",
"image": "my-repo/application",
"cpu": 100,
"memory": 100,
"essential": true,
"mountPoints": [
{
"sourceVolume": "application_logs",
"containerPath": "/var/log/exported"
}
]
}
],
...
}위와 같이 설정한다면 application1과 application2는 mount point를 통해 로그를 같은 위치에 쌓을 수 있다.
`efsVolumeConfiguration` 설정으로 EFS를 볼륨으로 사용할 수 있다.
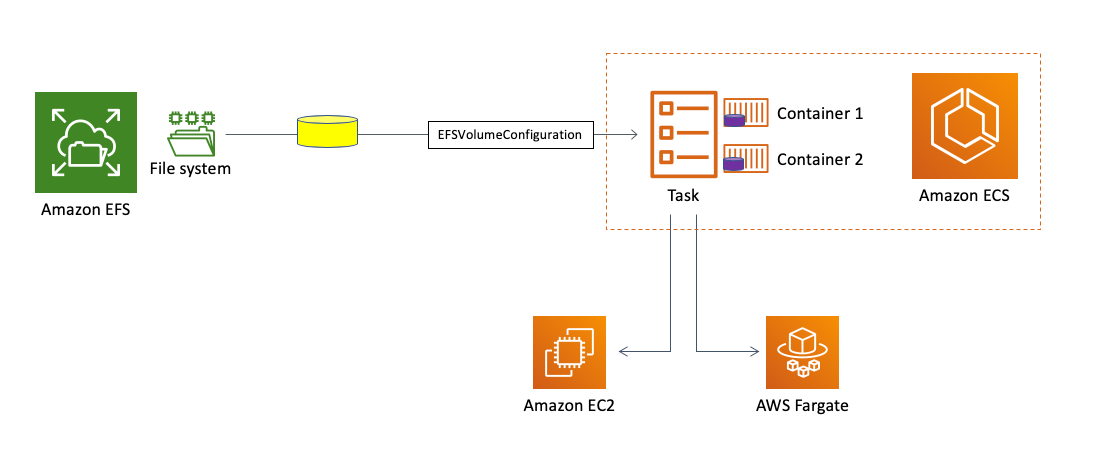
EBS와 EFS의 차이점은 Multi-AZ에 대한 지원 여부이다. EBS는 Multi-AZ가 지원되지 않기 때문에, EBS를 태스크와 상관없이 살리더라도 다른 가용영역에서 사용하기 위해선 스냅샷으로 카피를 해야한다. 반면, EFS는 Multi-AZ가 지원되기 때문에 수월하다.
EFS를 Fargate 유형의 ECS와 사용한다면 여러 태스크가 동시에 EFS 파일 시스템에 접근이 가능하니 가용성이나 확장성이 뛰어나지고, Regional 서비스인 S3 버켓에서 필요 시 데이터를 가져온다면 AWS 서비스에 충실한 서버리스 고가용성 애플리케이션을 완성할 수 있다.

Fargate
Fargate란 컨테이너를 사용한 AWS의 완전 관리형 서버리스 컴퓨팅 엔진이다.

컨테이너 기반의 서비스인 ECS나 EKS를 사용했을 때 Fargate 유형으로 서버리스 인프라를 사용함으로써 적절한 인프라 용량 등을 컨테이너 런타임이나 OS 등의 환경관리와 함께 서비스로서 제공 받는다. 사용자는 인프라를 사용하는 만큼 (pay-as-you-go) 지불을 하며 OCI 표준만 준수한다면 인프라가 아닌 애플리케이션의 관리에 집중할 수 있게된다.
Fargate Spot
Fargate Spot은 스팟 인스턴스를 제공하는 용량 공급자이다. Fargate Spot을 사용하면 EC2 스팟 인스턴스를 사용하는 것과 마찬가지로 여분의 스팟 용량을 사용할 수 있을 때 그것을 활용하며, 스팟 용량이 부족하다면 작업 시작이 지연되고 정상적으로 작업이 시작될 때까지 ECS 서비스가 태스크를 지속적으로 다시 시작한다.
Fargate Spot으로 동작 중인 스팟 용량이 중단된다면 태스크 중단 2분 전부터 EventBridge 경고가 전송되고, 이후 중단 시 태스크에는 프로그램 종료를 위한 `SIGTERM`이 전송된다. 즉각 종료가 아닌 유예기간을 가지기 위해 기본 30초로 설정된 `stopTimeout` 시간 만큼의 시간이 흐르면 `SIGKILL`을 통해 태스크는 즉시 종료된다. 태스크 종료 전에 해두어야 할 것이 있다면 `stopTimeout`을 최대 120초 이내에서 넉넉한 시간을 부여하고, `SIGTERM`에 대한 핸들러를 구현해두는 것이 바람직하다.
'DevOps > AWS' 카테고리의 다른 글
| [AWS] ECS Capacity Provider (0) | 2025.05.18 |
|---|---|
| AWS - ECS EC2 유형의 네트워크 모드 및 비용 (2) | 2025.05.01 |
| AWS - Elastic Container Registry(ECR) (0) | 2025.04.08 |
| AWS - Auto Scaling Group(ASG) (0) | 2025.03.08 |
| AWS - Elastic Load Balancer(ELB) & Elastic Beanstalk(EB) (0) | 2024.11.03 |