
AWS의 컨테이너 서비스인 ECS를 시작하기 위한 클러스터 유형으로는 서버리스인 Fargate 유형과 EC2 유형이 있다. EC2 유형은 인스턴스를 직접 관리하는 만큼 관리 포인트가 늘어나지만, 그만큼 비용 부담이 더 적다. EC2 유형의 큰 특징 중 하나는 네트워크 모드이고, 또 다른 하나는 Capacity Provider, 혹은 용량 공급자이다.
클러스터 오토스케일링과 서비스 오토스케일링
Capacity Provider를 이해하기 위해 오토스케일링에 대해 이해할 필요가 있다. 흔히 말하는 Auto Scaling Group (ASG)는 컴퓨팅 리소스인 EC2 인스턴스에 대한 오토스케일링 그룹이지만, 컨테이너 기반인 ECS에서 사용되는 오토스케일링은 클러스터 오토스케일링과 서비스 오토스케일링이 있다.
클러스터 오토스케일링
ECS 클러스터는 물리적인 인프라스트럭처를 포함한다. 클러스터 오토스케일링이란 서비스가 실행되기 위한 인프라의 오토스케일링이다. 위에 언급됐던 EC2 오토스케일링이라고 생각하면 된다.
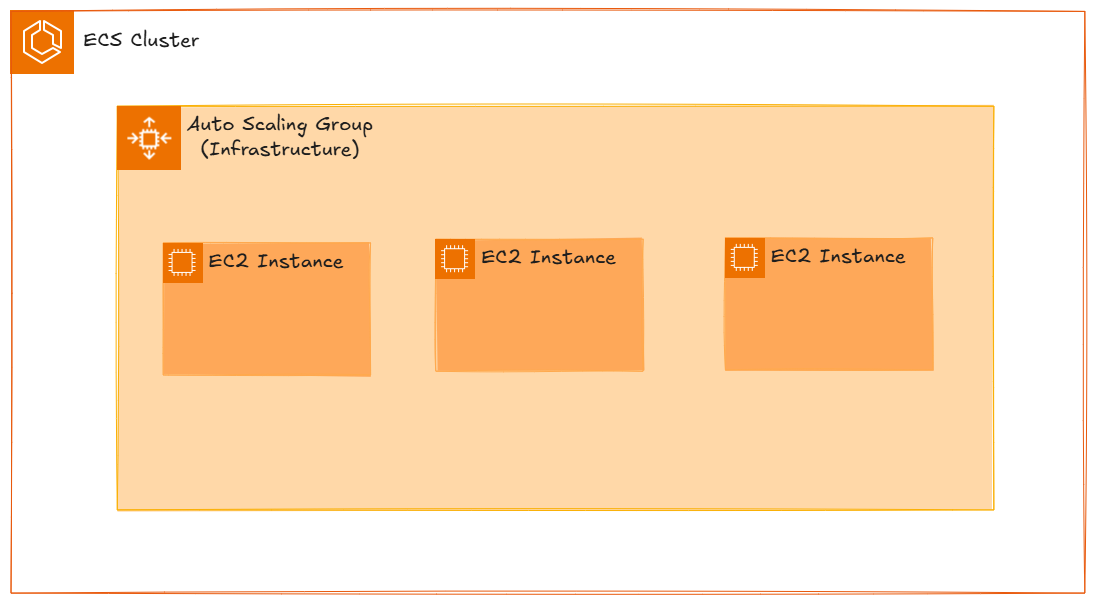
서비스 오토스케일링
ECS 클러스터로 구성된 인프라에 정의된 태스크 컨테이너를 구동할 수 있다. 태스크를 직접 올릴 수도 있지만, 태스크를 올릴 때의 배포 방식이나 다른 설정들을 포함해 태스크 배포를 관리하는 ECS 서비스를 통해 올릴 수도 있다. ECS 서비스를 사용할 때, 상황에 따라 태스크 컨테이너를 자동으로 스케일링 하는 것이 서비스 오토스케일링이다.

Capacity Provider
EC2 유형과 Fargate 유형 모두 서비스 오토스케일링을 타겟 메트릭이나 단계별 스케일링으로 설정할 수 있다. 하지만 태스크가 늘어나더라도 인프라 인스턴스가 부족하면 태스크를 실행할 수 없다. 반대로, 태스크가 줄더라도 인스턴스가 늘어난 채라면 불필요한 비용이 발생한다.
스케일링되는 태스크에 맞춰서 인프라 또한 늘어나거나 줄어들어야 하는 클러스터 오토스케일링이 진행되어야 하고, 두 오토스케일링 그룹 사이에서 이를 조절해주는 것이 Capacity Provider, 용량 공급자이다.

ECS 서비스의 서비스 오토스케일러가 태스크 수를 조절하면 서비스와 연결된 Capacity Provider가 클러스터 오토스케일러를 컨트롤하면서 인스턴스를 조정할 수 있다.
Fargate 유형의 Capacity Provider
Fargate 유형은 서버리스인 만큼 AWS가 인프라를 관리 제공한다. 그렇기 때문에 Fargate 유형의 Capacity Provider는 특별히 설정할 것이 없고 AWS에서 제공해주는 것을 사용하면 된다. 사용자는 태스크에 대한 오토스케일링만 신경 써주면, 그에 따른 클러스터는 AWS가 완전 관리하기 때문이다.
태스크 정의에선 vCPU와 메모리 등의 컨테이너 스펙을 정의할 수 있다. Fargate 유형에선 그렇게 정해진 컨테이너의 스펙에 딱 적절한 하드웨어를 제공받을 수 있다.
Fargate 유형의 Capacity Provider는 ECS 클러스터와 서비스를 생성하면서 선택할 수 있다. Fargate 유형의 ECS 클러스터를 만들고 ECS 서비스를 만들 때 Compute configuration에서 확인할 수 있다.

Capacity Provider는 Fargate 뿐만 아니라 Fargate Spot도 선택할 수 있다. Fargate Spot도 EC2 Spot 인스턴스랑 똑같이 불안하지만 저렴한 비용으로 인프라를 구성할 수 있다.
EC2 유형의 Capacity Provider
EC2 유형의 Capacity Provider는 Fargate처럼 단순하진 않다. 인스턴스 유형이 유연하지 않고, 한 인스턴스에서 여러 태스크 컨테이너를 구동할 수도 있다.

직접 EC2의 ASG를 구성하고 Capacity Provider를 ECS 서비스와 ASG 간 연결해서 클러스터와 태스크 서비스들의 오토스케일링을 조정해야한다. 이를 위해 먼저 ASG와 Capacity Provider가 필요한데, ECS 클러스터를 구성하면서 만드는 것이 가장 자연스럽고 안전하다.
인스턴스 ASG 및 Capacity Provider 생성
ECS 클러스터를 생성하면서 EC2 인스턴스 유형을 선택하면 자연스럽게 새로운 ASG를 만들 수 있다.
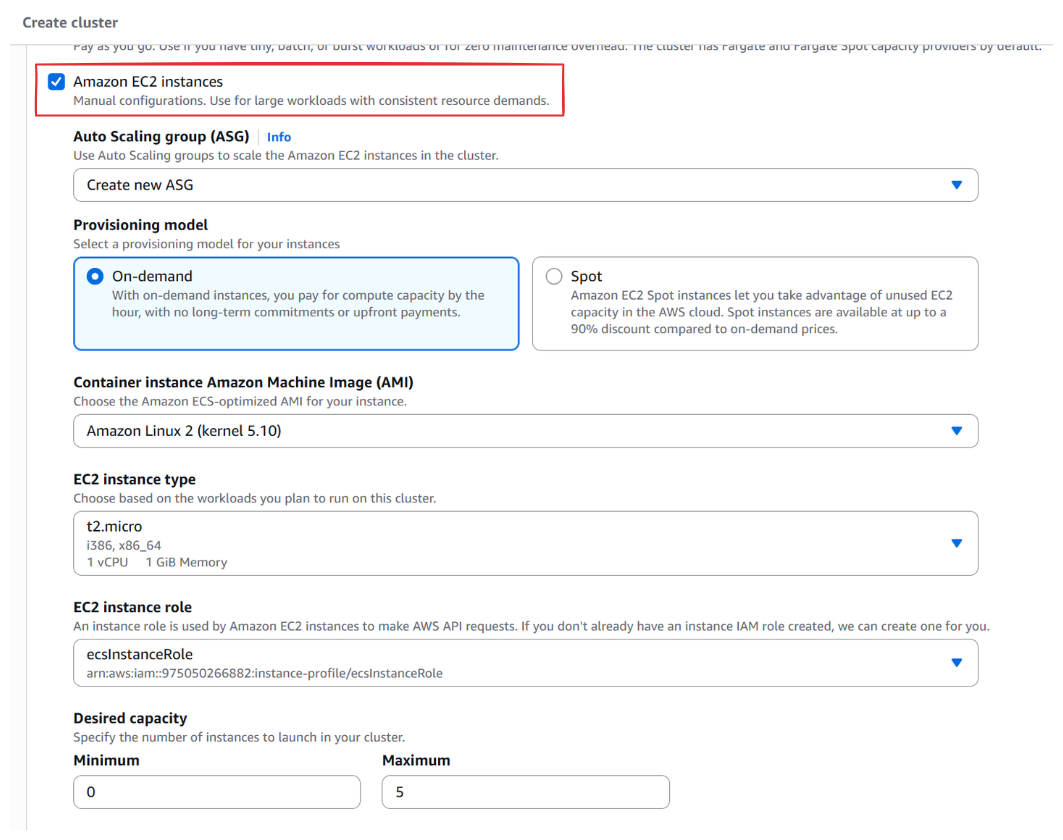
ECS 클러스터를 생성하면서 ASG를 생성하면 이 ASG에 연결되는 Capacity Provider도 생성된다. 연결된 Capacity Provider는 태스크 인스턴스가 늘어나서 클러스터 인스턴스가 필요할 때 ASG에 capacity 수를 조절해 인프라 용량을 공급한다. EC2 인스턴스가 필요한 IAM role도 이 과정에서 만들 수 있다.
ECS Agent와 최적화된 AMI
위의 EC2 인스턴스의 ASG에 등록되는 EC2 인스턴스는 ECS 서비스의 태스크를 구동할 수 있는 인프라로 등록되어야한다. 즉, ASG에 등록되는 것과는 별개로 ECS에 등록되어야 ECS 서비스에선 프로비저닝 중인 태스크를 등록된 인프라에 동작시킬 수 있다. 이러한 인스턴스가 어떤 클러스터에 어떻게 등록되는 지 등 ECS에 등록하는 과정을 담당하는 것이 ECS Agent이다. ECS Agent는 도커 위에서 돌아가는 프로세스이며, AWS가 개발해 오픈소스로 내놓은 컴포넌트이다.
GitHub - aws/amazon-ecs-agent: Amazon Elastic Container Service Agent
Amazon Elastic Container Service Agent. Contribute to aws/amazon-ecs-agent development by creating an account on GitHub.
github.com
AWS가 제공하는 AMI에는 이러한 ECS Agent가 포함되어 실행되는 ECS-Optimized AMI가 있다.

ECS-Optimized AMI를 기반으로 만들어진 인스턴스는 ECS에서 배포하는 태스크 컨테이너와 ECS Agent가 동작할 것이며, ECS 클러스터를 구성하면서 EC2 ASG를 만들 때 최적화된 AMI를 선택할 수 있다. 만약 별도로 ASG를 만들어서 ECS 클러스터에 붙인다면, 인스턴스 부트스트랩 시 설정이 필요하기도 하고 여러 사이드 이펙트가 발생할 수 있다.
ASG Capacity 범위와 Desired Capacity
ASG Capacity는 절대적이다. 인스턴스 수는 항상 최소 Min Capacity에 맞춰 실행되고, 최대 Max Capacity를 넘을 수 없다. ASG에도 Desired Capacity가 있지만, Capacity Provider와 연결된 ASG는 절대적인 Desired Capacity를 갖지 못한다. 연결된 Capacity Provider가 태스크에 따라 용량이 더 늘어야 할 땐 ASG의 Desired Capacity를 조절해서 인스턴스 수를 조절하기 때문이다. 하지만 아무리 프로비저닝 된 태스크가 많더라도 ASG의 Max Capacity는 넘지 못한다.
항상 일정한 수의 인스턴스를 보장하고 싶다면 ASG가 아닌 태스크를 조절해서 일정한 수의 인스턴스를 유지해야한다. EC2 ASG가 아닌 ECS 서비스의 Desired Capacity는 태스크 수의 목표 용량이다. 이를 조절해서 일반적인 인스턴스 수를 관리해야한다.
Capacity Provider와 ASG
ECS 클러스터를 생성하며 ASG를 생성했다면 연결된 Capacity Provider도 생성된다. 콘솔 상에선 클러스터로 들어가 Infrastructure를 확인하면 Capacity Provider를 확인할 수 있다.
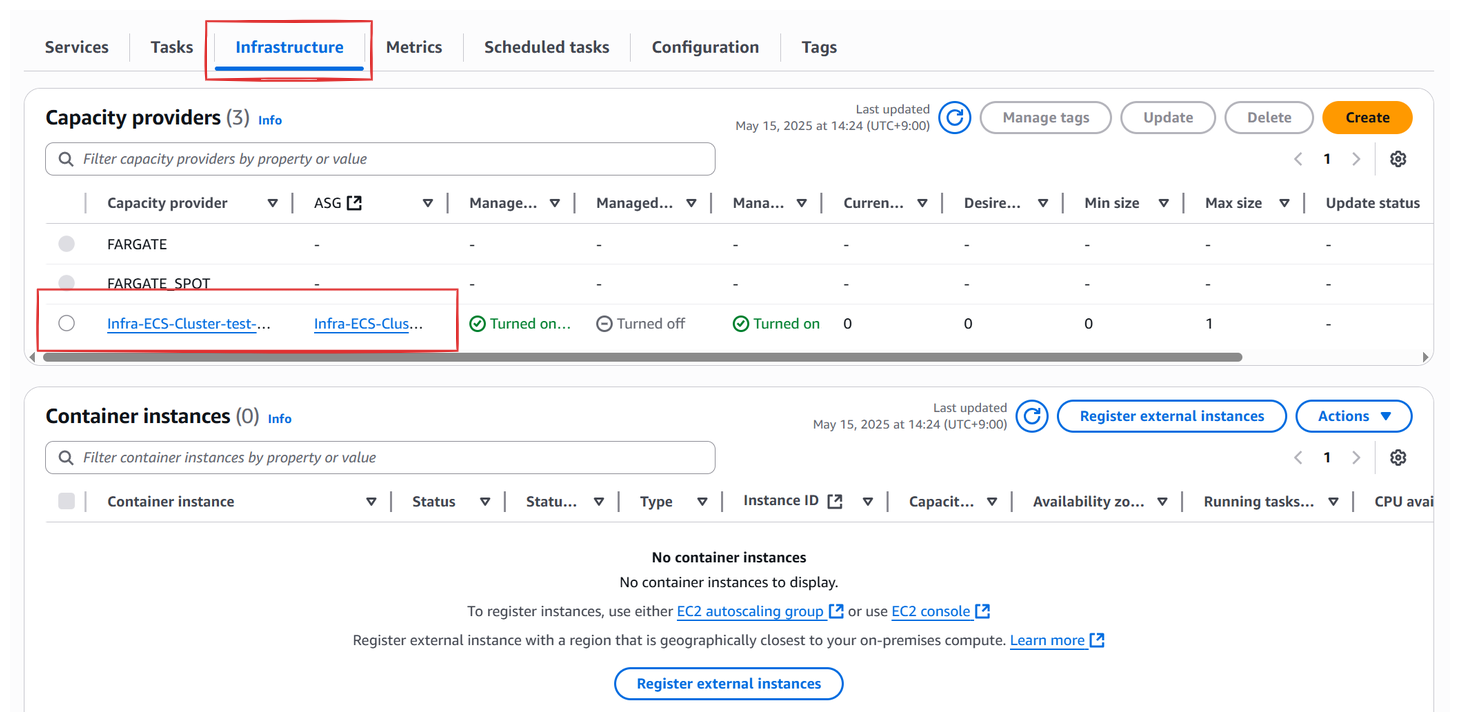
`FARGATE`와 `FARGATE_SPOT`은 AWS가 기본적으로 제공하는 것이기 때문에 항상 존재하는 것이고, EC2 유형의 ECS 클러스터를 생성할 때 만들었던 ASG와 연결된 Capacity Provider가 추가된 것을 확인할 수 있다. 해당 Capacity Provider를 클릭하면 상세조회가 가능하다.
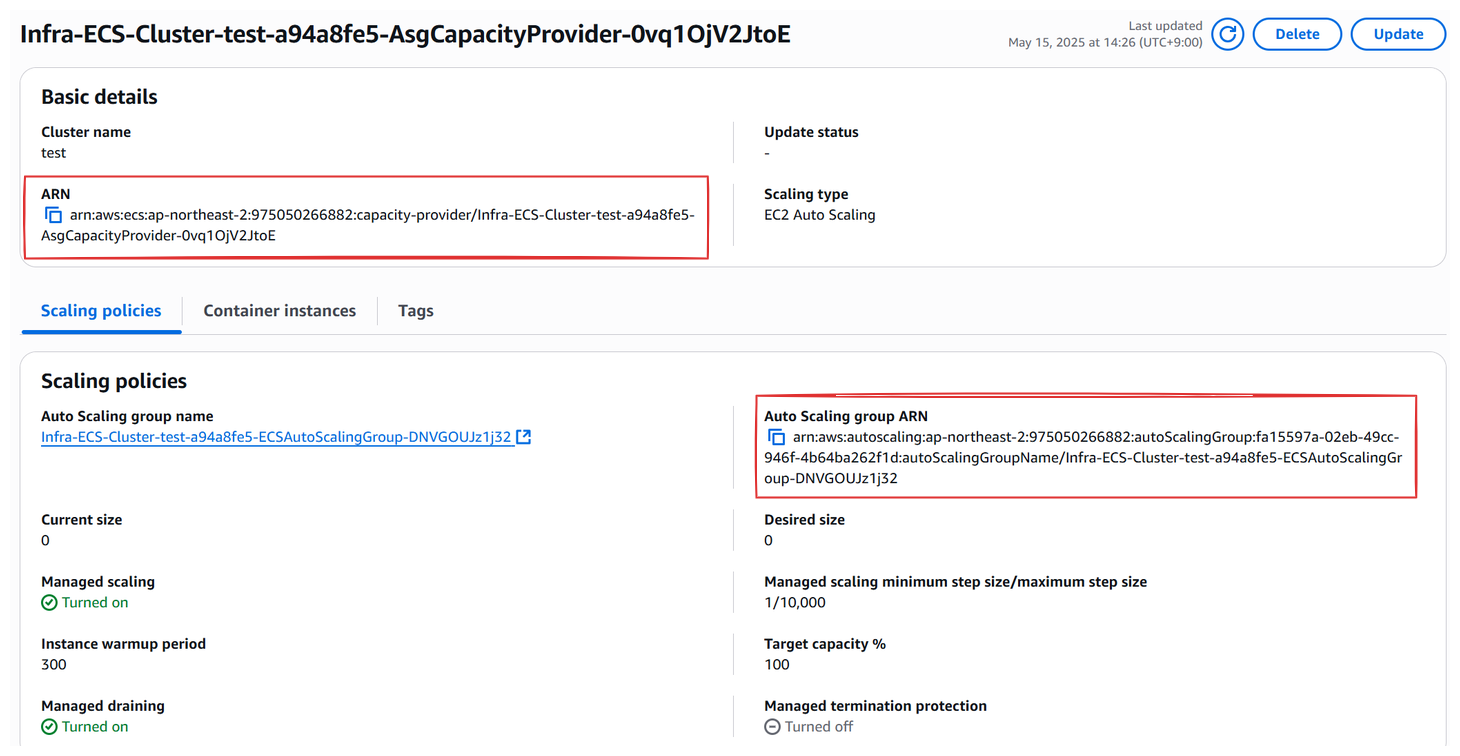
Capacity Provider를 확인해보면 리소스 고유의 식별번호인 ARN을 확인할 수 있다. Capacity Provider의 ARN 뿐만 아니라 연결된 ASG의 이름과 ARN 또한 확인할 수 있다.
보다시피 ASG와 Capacity Provider의 ARN이 다르다. 처음 공부할 때 ECS 클러스터로 ASG를 만들다보면 Capacity Provider와 ASG가 같다고 생각할 수도 있는데, 두 리소스는 다른 것을 확인할 수 있다.
ASG는 타겟 트래킹이나 단계별 스케일링 등 동적이나 정적 스케일링 정책을 설정할 수 있다. 위의 Capacity Provider와 연결된 ASG에 들어가 스케일링 정책을 확인해보면, 동적 스케일링 정책이 하나 생겨있다.

Capacity Provider와 자동 연결되어 만들어진 ASG이기 때문에 고유한 스케일링 정책이 존재하리라 예상할 수 있었겠지만, 정책 유형을 확인해보면 Target tracking scaling이다. 타겟 트래킹은 CPU 사용량이나 메모리 사용량, 로드밸런서 요청 수 등 특정한 CloudWatch 메트릭을 트래킹해서 일정 수준을 유지하게끔 스케일링하는 정책이다. Capacity Provider와 연결된 ASG는 어떠한 메트릭을 추적하는 것일까?

기본적인 CloudWatch 메트릭이 아닌 Custom 메트릭으로 되어있다. 내가 만든 적은 없지만 `CapacityProviderReservation`이라는 메트릭을 추적하며 해당 메트릭이 100이 되는 것을 목표로 스케일링한다.
Capacity Provider는 연결된 ASG 내에 등록된 인스턴스를 ECS 클러스터에 등록해 태스크를 실행할 수 있도록 하고, ASG는 해당 Capacity Provider의 `CapacityProviderReservation`이라는 메트릭을 모니터링해서 100이 될 수 있도록 인스턴스를 늘리거나 줄인다.
CapacityProviderReservation
`CapacityProviderReservation`을 구하는 공식은 다음과 같다.
CapacityProviderReservation (%) = (M / N) * 100
M = ECS 서비스의 태스크들을 모두 가용하기 위한 인스턴스 수
N = 현재 ASG에 가용되는 인스턴스 수
쉽게 말하면 M은 필요한 인스턴스 수고, N은 현재 인스턴스 수며, `CapacityProviderReservation`은 인스턴스가 얼마나 더 필요한지를 나타내는 백분율이다.
필요하다는 기준은 ECS 서비스의 태스크이다.
가용해야 할 태스크가 많아서 필요한 인스턴스 수(M)가 현재 가용되는 인스턴스 수(N)보다 많다면 M이 N보다 커져(M > N) `CapacityProviderReservation`은 100을 넘는다.
반대로, 태스크가 적어서 필요한 인스턴스 수(M)가 현재 가용되는 인스턴스 수(N)보다 적다면 M이 N보다 작아져 (N < M) `CapacityProviderReservation`은 100보다 아래가 된다.
만약 현재 인스턴스 수(N)가 필요한 인스턴스 수(M)만큼만 있다면 M은 N과 같아져(M = N) `CapacityProviderReservation`은 100%가 되고, 일반적으로 이 수치가 ASG가 목표하는 수치이다. 즉, 필요한 만큼만 인스턴스를 올리는 것을 목표로 한다.
Scale-out
인스턴스 스케일 아웃의 예시를 들어보겠다.

보라색 박스는 EC2 인스턴스이고 초록색은 태스크이다. 현재는 3개의 EC2 인스턴스가 돌아가고 6개의 태스크는 세 인스턴스 위에서 돌아가는 상황이다. M = 3이고, N = 3으로 `CapacityProviderReservation`은 100%이다.
태스크 수가 급격하게 늘어 9개의 태스크가 추가되면 상황은 아래와 같다.
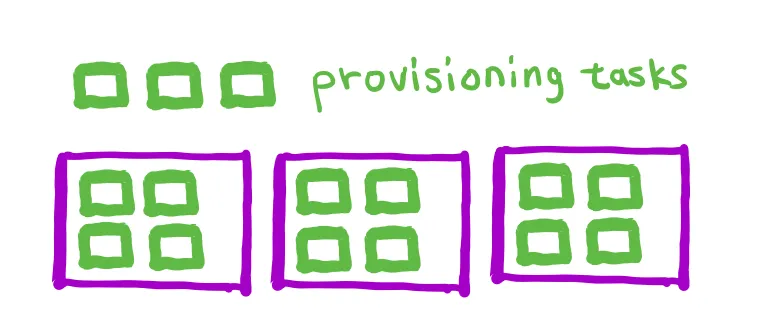
인스턴스에는 가능한 태스크 컨테이너가 모두 돌아가고 추가로 3개의 태스크가 프로비저닝된 상태이다. 현재 가용되는 인스턴스 수는 3개이므로 N = 3이고, 인스턴스 하나에 태스크가 4개까지 돌아간다고 가정하면 필요한 인스턴스는 4개로 M = 4이다. `CapacityProviderReservation`은 (4 / 3) * 100으로 133%가 된다.

태스크가 늘어나면서 현재의 인스턴스에서 가용될 수 있는 태스크 컨테이너는 바로 돌아가겠지만, 인스턴스가 모두 차면 그 이후의 태스크는 프로비저닝 상태로 인스턴스가 등록될 때까지 기다리게 된다.
ASG는 `CapacityProviderReservation`을 100%로 맞추기 위해 하나의 인스턴스를 추가로 생성하고 Capacity Provider는 해당 ASG의 인스턴스를 ECS 클러스터의 인프라로 등록한다. 그렇게 되면 프로비저닝 상태의 태스크들은 등록된 인프라에서 정상적으로 컨테이너를 가용할 수 있다.

Daemon
태스크 컨테이너 중 Daemon으로 동작하는 태스크가 있다. ECS 서비스를 생성하면서 Capacity Provider를 선택하지 않고 태스크를 바로 실행할 수 있는 Launch type 옵션을 선택하고 EC2 용량을 선택하면 Daemon 유형을 선택할 수 있다.
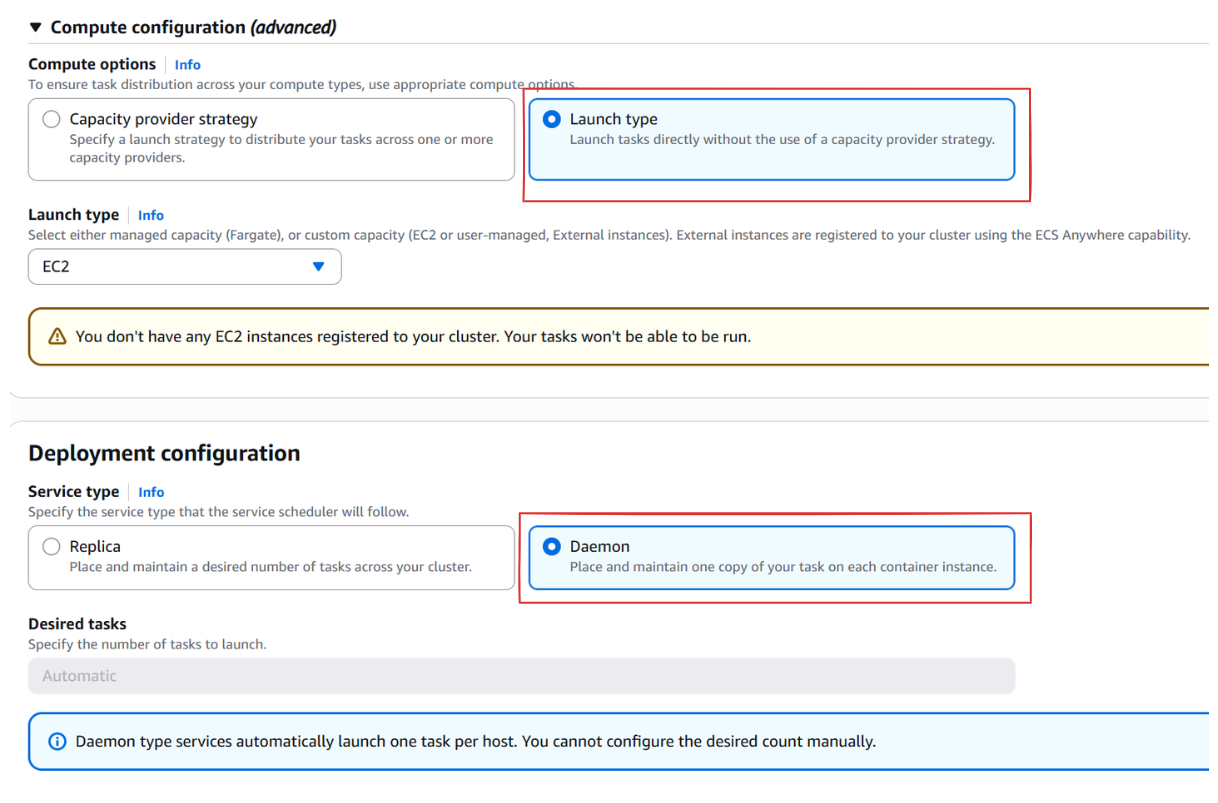
Replica는 특정한 수를 목표로 태스크 수를 유지하지만, Daemon 유형은 특정한 인스턴스에 컨테이너를 실행시킬 수 있다.
유형이 Launch type이니 Capacity Provider가 관리하는 영역의 밖이다. 즉, EC2 인스턴스에서 daemon 유형의 컨테이너가 동작하고 있더라도 Capacity Provider가 관리하는 태스크가 없다면 필요없는 인스턴스가 된다.
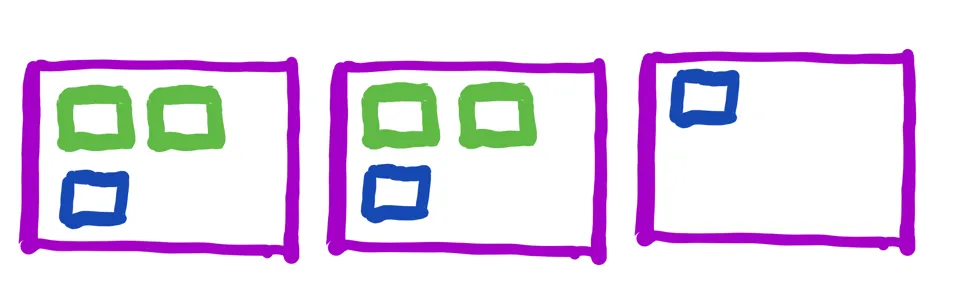
초록색은 Capacity Provider 유형의 서비스가 관리하는 태스크 컨테이너고, 파란색이 daemon 유형의 태스크 컨테이너다. 현재 Capacity Provider가 인식하기에 필요한 인스턴스 수는 초록색만을 포함한 두개의 인스턴스이므로 M = 2가 되고, 현재 인스턴스 수인 N = 3이 된다. Daemon 컨테이너가 동작하고 있더라도, Capacity Provider와 ASG는 필요없는 인스턴스가 하나 추가로 존재한다고 생각하고, `CapacityProviderReservation`은 (2 / 3) * 100으로 66%가 된다.
Scale-in
위와 같은 상황에서 `CapacityProviderReservation`이 100보다 낮아진다.

66%로 낮아진 `CapacityProviderReservation`을 100%로 맞추기 위해선 M = 3으로 증가하거나 N = 2로 감소해야한다. 태스크 수에 따라 필요한 인스턴스 수는 정해져 있으니, N을 2로 감소시키기 위해 ASG는 인스턴스를 하나 줄이게 된다.

Capacity Provider와 연결된 ECS 서비스가 관리하는 태스크 컨테이너는 스케일 인으로 부터 보호 받는다. ASG는 Capacity Provider가 인지할 수 있는 태스크가 없는 인스턴스를 종료하게 된다.
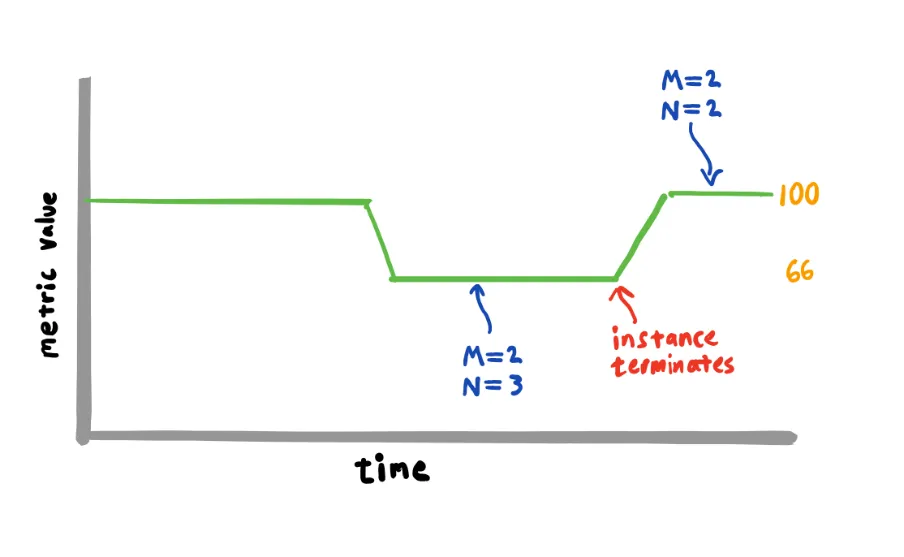
이렇듯 ASG는 Capacity Provider의 메트릭을 읽어 인스턴스 수를 조절하게 된다.
N = 0 일 때
한가지 사소한 점이 있다면 N = 0일 때이다. N은 `CapacityProviderReservation` 계산식에서 분모로 들어가므로 N = 0일 때는 정상적인 계산이 되지 않는다. 이럴 때 태스크가 새롭게 시작된다면(M > 0) `CapacityProviderReservation`은 200%가 된다. 필요한 인스턴스보다 두배의 인스턴스를 생성한다는 의미이다. 새롭게 태스크가 시작된 후 필요한 인스턴스가 1개라면 2개의 인스턴스가 새로 생기고, 필요한 인스턴스가 2개라면 4개의 인스턴스가 새로 생긴다. 이후 ASG는 `CapacityProviderReservation`을 100%로 줄이기 위해 필요없는 인스턴스를 종료한다. 이 과정은 일반적으로 10~30분 정도 걸리는 것 같다.
Capacity Provider가 태스크 수와 인스턴스 수를 조절하는 법
사실 N은 명확하다. 물리적으로 현재 가용되는 인스턴스 수이다. 하지만 M은 명확하지 않다. 위의 예시들에선 그럴싸해보이지만, 사실 복합적이다. 태스크 정의에선 컨테이너의 vCPU와 메모리를 유연하게 정할 수 있다. 반면 EC2 인스턴스 유형들은 vCPU와 메모리가 고정이다. 새로운 태스크가 현재 있는 인스턴스에 남은 용량에 맞을 수도 있고, 아닐 수도 있다.
계산 또한 사실 단순하지 않다. 예를 들어 1vCPU와 2GB 메모리의 컨테이너를 실행하기 위해서 필요한 인스턴스는 1vCPU에 2GB + @이다. 인스턴스의 OS나 기타 소프트웨어 등 필요한 초기 리소스가 있기 때문이다.
Fargate의 경우엔 컨테이너의 스펙에 맞춘 컴퓨팅 스펙을 자동으로 제공하겠지만, EC2 유형은 사용자가 직접 관리해야한다.
Task Placement Strategy
콘솔에서 ECS 서비스를 생성할 때 옵션을 보면 Task Placement라는 옵션이 있다.
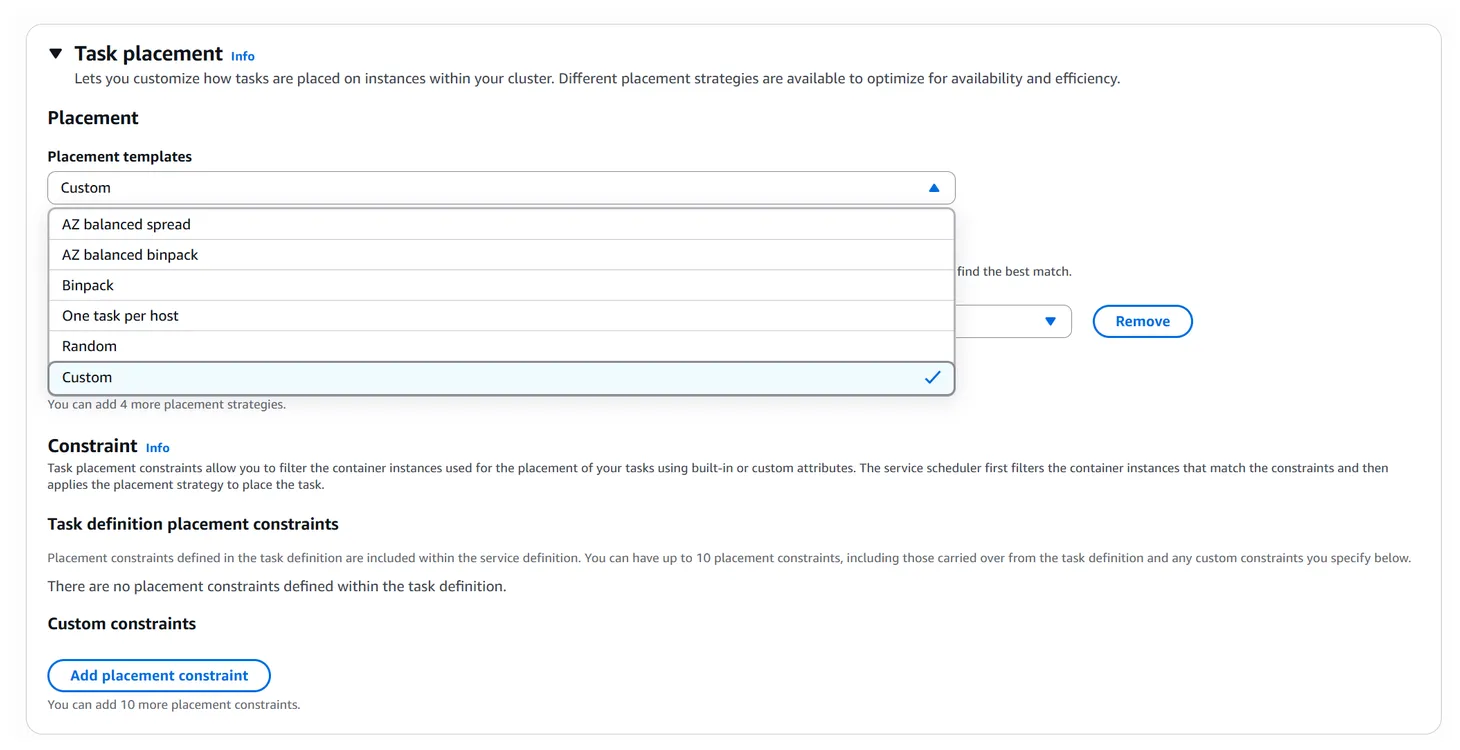
여러 AZ에 균형을 맞추는 AZ balanced spread/binpack이 있고, 일반 Binpack, 호스트 당 하나의 컨테이너만 실행하는 One task per host, 아예 무작위인 Random, 그리고 사용자 정의인 Custom을 선택할 수 있다.
Custom을 선택하면 전략을 세가지 중에서 선택할 수 있다.

Spread, Binpcak, Random 이렇게 세가지 중 하나의 유형을 골라서 선택할 수 있다. 템플릿과 커스텀 유형에 공통적으로 나오는 Spread와 Binpack, Random에 대해 알아보겠다.
Spread
Spread 옵션은 수를 균형있게 분산하는 것이다.
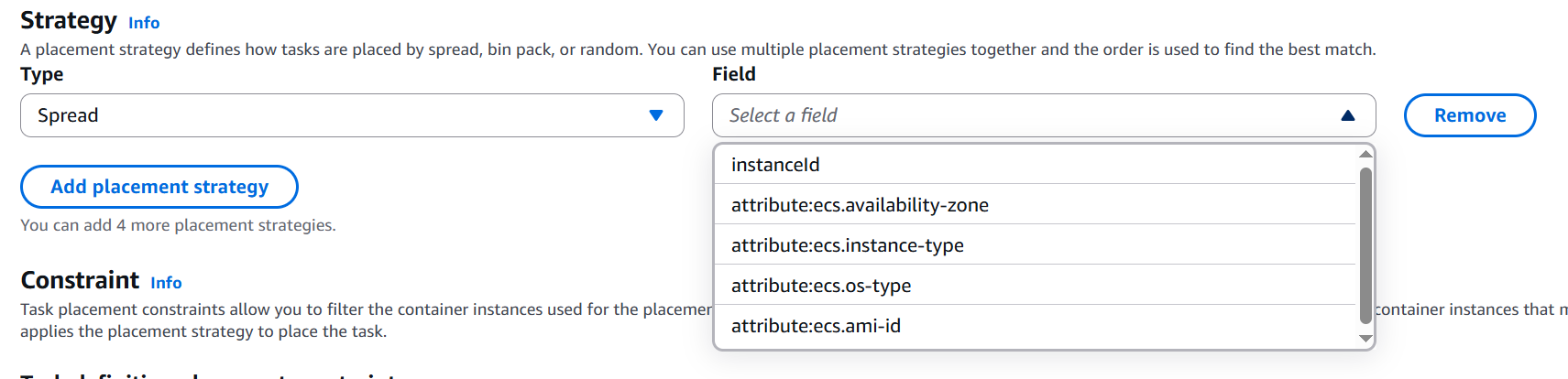
기준이 되는 필드는 위와 같이 정할 수 있는데, AZ에 알맞게 퍼뜨리거나 인스턴스 유형, 혹은 등록된 인스턴스 ID 별로 태스크 수를 균형있게 퍼뜨리는 옵션이다. 실제 리소스 스펙의 가능 여부와 상관없이 수를 균형있게 퍼뜨리는 옵션이다.
작업 배치 전략을 선택하지 않으면 ECS 서비스의 기본값으로는 AZ를 사용한 spread 전략이 적용된다.
Binpack
Binpack 옵션은 특정한 기준점을 가지고 태스크를 배치한다.

CPU나 메모리 등을 기반으로 가용가능한 인스턴스부터 꽉꽉 채워나가는 배치 유형이다. 일반적으로 AWS에서도 이러한 binpack 옵션을 추천하고, 가장 리소스를 효율적으로 사용할 수 있는 옵션이다.
CPU 사용량보다 사실 메모리를 기준으로 하는 것이 낫다. 인스턴스 별로 가용가능한 메모리는 표기된 수치보다 낮기 때문이다. 2GB라면 실제로 가용가능 한 것은 1.8GB 정도이다.
Random
말 그대로 무작위로 배치하는 유형이다.
배치 전략을 한가지만이 아니라 여러가지로 구성해 우선순위를 두어 설정할 수도 있다. 예를 들어 메모리의 binpack을 최우선으로 하고 instance id의 spread 전략을 추가로 넣어 구성한다면, 메모리를 기반으로 태스크를 인스턴스에 배치하되 인스턴스들의 메모리 사용량이 같아지면 두번째 기준으로는 spread 전략이 적용되어 인스턴스 별로 수를 균형있게 맞추는 전략이 된다.
Constraint
배치 전략 뿐만 아니라 제약도 둘 수 있다.
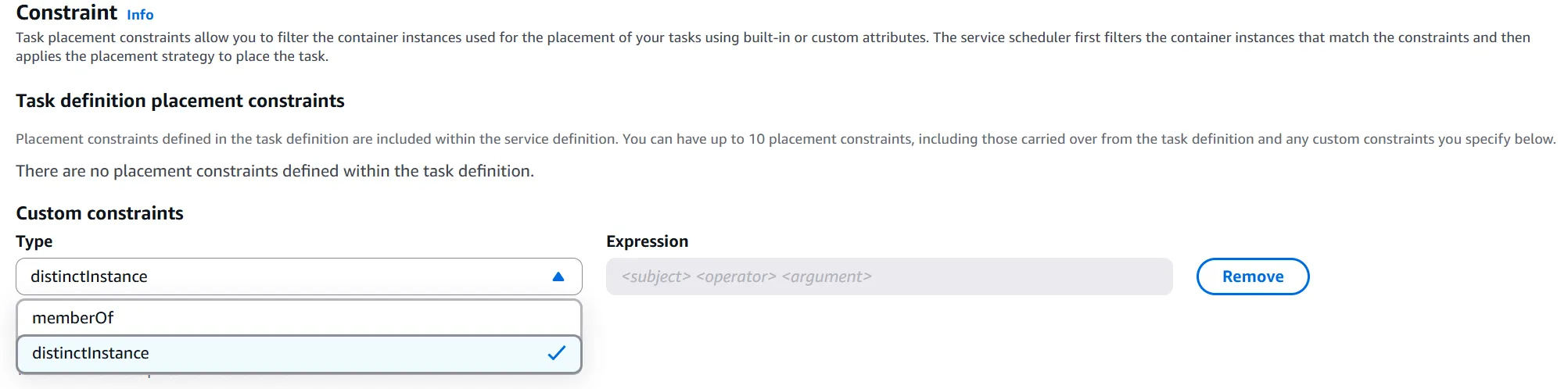
해당 Capacity Provider는 memberOf를 통해 특정한 EC2 인스턴스에만 두거나 혹은 distinctInstance로 태스크들을 서로 다른 인스턴스에 등록해 격리를 유지할 수도 있다.
사실 위의 작업 배치 전략으로 M 계산법을 선택할 수 있는 것은 아니다. 만약 태스크가 생기고 인스턴스 리소스에 여유가 있을 때 어떻게 작업을 배치할 지에 대한 전략일 뿐이다. M을 계산하는 방법을 이해하기 위해 위의 전략들과 제약에 대해 이해할 필요가 있다.
Grouping을 통한 M 계산법
프로비저닝된 태스크가 존재한다면 현재 가용중인 인스턴스 외에 필요한 인스턴스 수를 계산해야된다. M 계산법은 사실 나와있는 것도 없고 복잡하다. 개념적으로만 이해하자면, 태스크들을 grouping해서 각 그룹의 vCPU, 메모리 등의 리소스를 기반으로 계산한다. 이렇게 계산된 각 그룹의 리소스를 ASG의 인스턴스 유형을 기반으로 인스턴스가 몇개가 필요한지 최적의 값을 내어 M을 구하는 것이다. 위에서 설정한 제약이 있다면, 이 제약도 반영된다. 즉, 제약을 반영한 binpack 전략을 기반으로 계산이 된다.
예를 들어, 3개의 태스크가 있다고 가정해보자.
| 태스크 | vCPU | Memory |
| Task A | 0.5 vCPU | 1 GiB |
| Task B | 1.5 vCPU | 2 GiB |
| Task C | 1 vCPU | 2 GiB |
그리고 ASG에서 사용하는 인스턴스 유형이 `t3.medium`일 때, 3개의 태스크를 여러 조합으로 grouping 해서 리소스들을 합쳐 `t3.medium` 기반으로 몇 개의 인스턴스가 필요한지 최적의 값을 계산한다.
| Group | vCPU | Memory | 가능여부 |
| A + B | 2.0 | 3.0 GiB | ✅ |
| A + C | 1.5 | 3.0 GiB | ✅ |
| B + C | 2.5 | 4.0 GiB | ❌ |
| A | 0.5 | 1.0 GiB | ✅ |
| B | 1.5 | 2.0 GiB | ✅ |
| C | 1.0 | 2.0 GiB | ✅ |
이렇게 되면 A+B 그룹의 인스턴스 한 개와 C 태스크 인스턴스 한 개로 총 두 개의 인스턴스가 더 필요하게 되고, M은 N + 2가 된다. 이는 예시로 나타내는 계산법이고, 실제로는 더 복잡할 것이다.
이렇게 계산된 M에 따라 `CapacityProviderReservation`이 계산되고, 필요한 인스턴스가 ASG를 통해 생성된다. 그 후 태스크들을 인스턴스들에 배치할 때 적용되는 것이 배치 전략이다.
ASG의 인스턴스 유형
ASG는 한 가지 이상의 인스턴스 유형을 선택할 수 있다.

이러면 계산법이 조금은 더 복잡해지긴한다. 우선 인스턴스 유형의 리소스에 따라 정렬시켜 태스크 grouping 별로 계산을 해보고, 가장 작은 그룹도 수용하지 못 하는 인스턴스 유형은 배제하면서 최적의 인스턴스 수를 계산한다.
이러한게 있구나 정도만 알면 좋고, 계산법이 binpack 기반이므로 실제 작업 배치 전략도 메모리 기반의 binpack을 사용하는 것이 좋다.
Multi Providers
ECS 서비스를 생성할 때 EC2 유형이나 Fargate 유형이나 Capacity Provider를 설정해야한다.
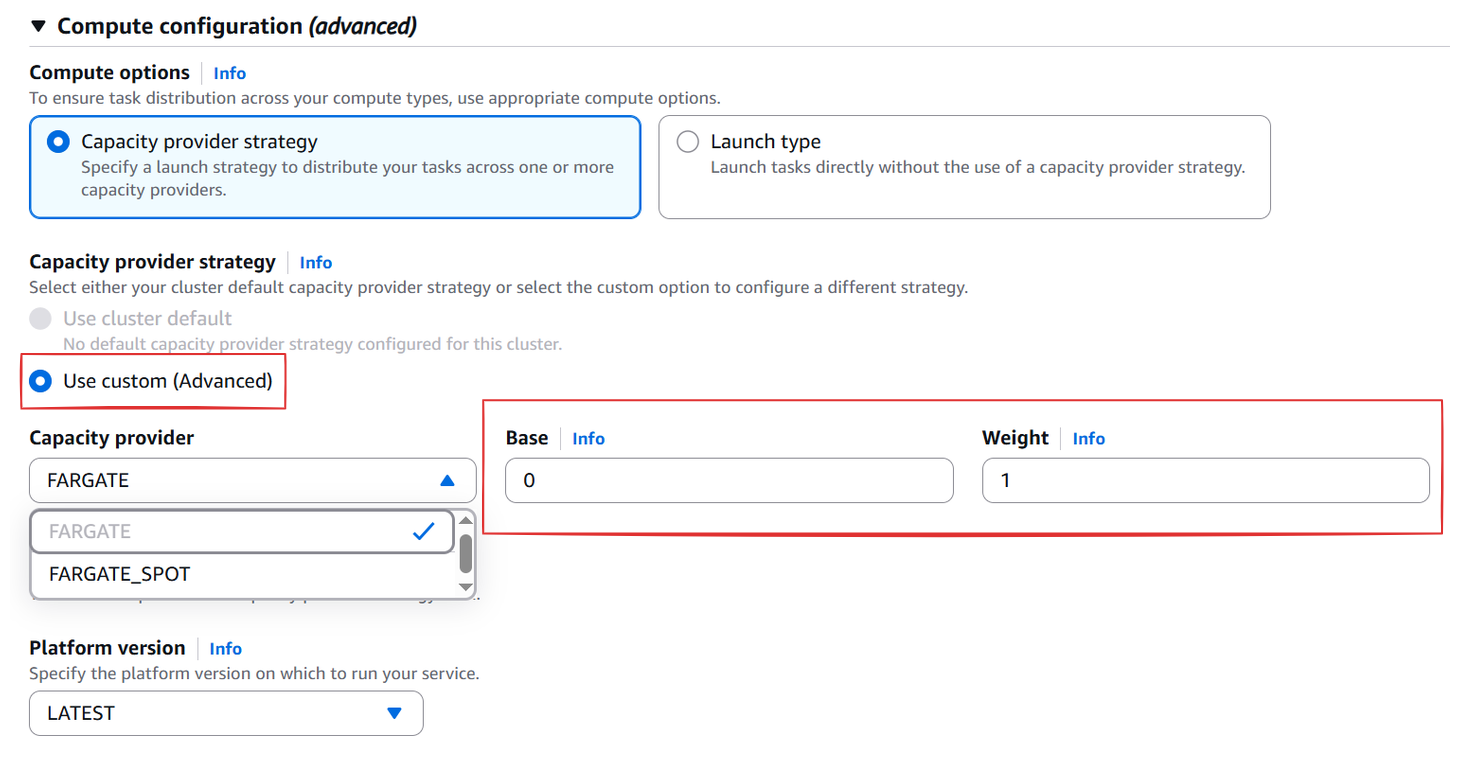
EC2 유형은 아마 클러스터를 생성하며 생성된 ASG에 연결된 Capacity Provider를 사용하는 것이 기본으로 되어있을 것이다. Custom 전략으로 바꾸면 아래와 같이 Capacity Provider를 선택할 수 있고, 그 옆에는 Base와 Weight라는 것이 있다. 이 두 값은 ECS 서비스를 구성할 때 Capacity Provider를 여러개 사용할 때 유의미하게 쓰이는 값이다.
Base
Base는 ECS 서비스에서 해당 Capacity Provider에 배치될 최소한의 태스크 수 베이스라인이다. 예를 들어, 만약 base가 10이라면 초기 10개의 태스크는 이 Capacity Provider에 의해서 용량 공급이 이루어진다.
Weight
Weight는 가중치이다. 각 Capacity Provider의 베이스라인에 맞춰 우선적으로 태스크가 분산된 후, 그 이상의 태스크 컨테이너가 배포될 때 Capacity Provider들에 분산될 비율이다. 만약 A Capacity Provider가 1의 weight를 가지고, B Capacity Provider가 2의 weight를 가진다면, 베이스라인을 넘은 태스크들 중 2개가 B Capacity Provider, 1개가 A Capacity Provider에 의해 용량 공급이 이루어진다.
Weight는 프로비저닝 된 태스크들을 분산시키기 위한 비율일 뿐, 정확한 예상은 힘들다. 아래의 예시를 통해 이해가 더욱 잘 됐으면 좋겠다.
예시
첫번째 예시는 Capacity Provider가 하나만 존재할 때이다.
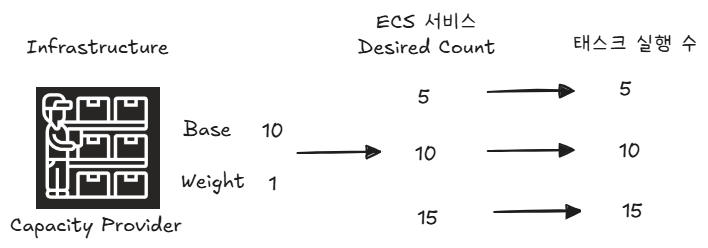
Capacity Provider가 하나만 존재할 땐, base와 weight가 유의미한 값은 아니다.
두번째 예시는 Capacity Provider A가 base만 있고 Capacity Provider B는 weight만 값이 있을 때이다.

ECS 서비스의 desired count가 초기에 5개로 되어있다면 A의 베이스라인이 적용돼 모두 A의 용량을 통해 배포된다. 만약 desired count를 직접 바꾸거나 서비스 오토스케일링을 통해 10개로 바뀐다면, 아직 A의 베이스라인이기 때문에 모두 A의 용량을 통해 배포된다. 10개 이상의 태스크가 생기면, 10개까지는 base에 맞춰 A에 배포되고 이후 weight의 비율에 따른다. A:B는 0:1이므로 10개 이후의 태스크는 모두 B의 용량에 배포된다.
위의 예시에서 A의 weight가 0이 아닐 때의 예시는 이렇다.
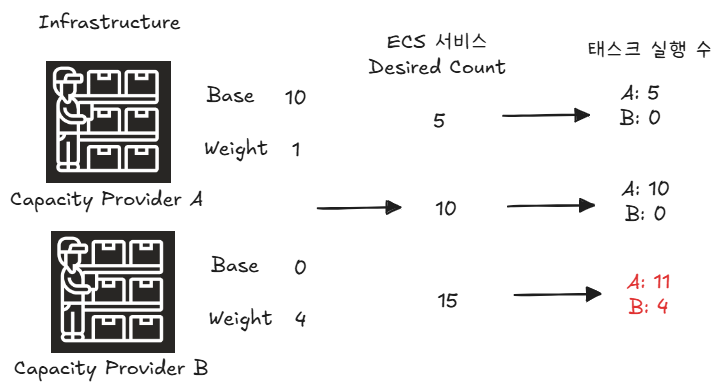
초기 10개의 태스크 컨테이너는 베이스라인에 따라 모두 A의 용량에 배포된다. 이후 desired count가 15개가 됐을 때, 10개 베이스라인을 초과한 5개의 태스크에 대해선 1:4의 비율이 적용되어 A에는 1개, B에는 4개의 태스크가 배포된다.
만약 A와 B 모두 Base 값이 존재하면 어떨까?
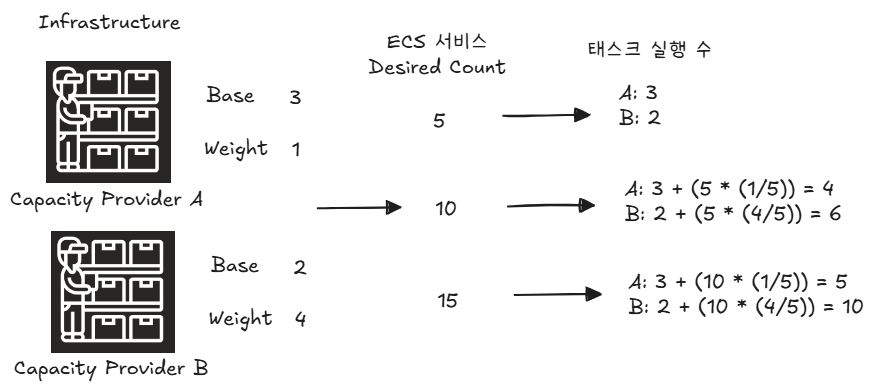
초기 5개는 A와 B의 base에 맞춰 각각 3개, 2개로 배포가 될 것이다. 추가 태스크들에 대해선 1:4의 비율이 그대로 적용되어 위와 같이 각 용량 공급자에 의해 배포가 된다.
하지만 base는 사실 수치일 뿐이고 어느 Capacity Provider가 선택되는지는 정확히 알 수 없다. 일반적으로 base 수치가 더 큰 Capacity Provider를 통해 배포되는 것으로 예상이 되지만, 정확하진 않다. 그리고 weight는 단순히 비율일 뿐이다. 그렇기 때문에 수치가 정수로 떨어지지 않을 수도 있다.

두 Capacity Provider 모두 1의 base를 가질 때 1개의 태스크가 실행된다면, 이것이 A에 배포될지 B에 배포될지는 정확히 예상하기 힘들다. 2개의 태스크가 실행된다면 각각의 base에 맞춰 A와 B 모두 1개의 태스크를 배포할 것이다. 만약 desired count가 5가 되어 base보다 3개의 태스크가 더 늘어난다면, 3개의 태스크에 비율을 적용한 수치는 A와 B 각각 0.6과 2.4가 된다. 하지만, 0.6개의 태스크와 2.4개의 태스크는 될 수 없으니 A에 1개, B에 2개, 혹은 B에 3개가 배포될 수도 있다. 하지만 정확한 액션을 알 수 없다.
이에 대한 정확한 액션은 굳이 알 필요 없다고 생각한다. 여러 Capacity Provider를 사용한다면 굳이 나누어서 base를 두는 것도 관리가 힘들어지기에 한 Capacity Provider에만 base를 주고, 나머지는 0으로 두는 것이 바람직할 것이라고 생각한다. Weight 비율에 따른 오차 또한 감수해야한다.
유용하게 사용될 수 있는 예시는 Fargate와 Fargate Spot을 사용하는 것이라고 생각한다.
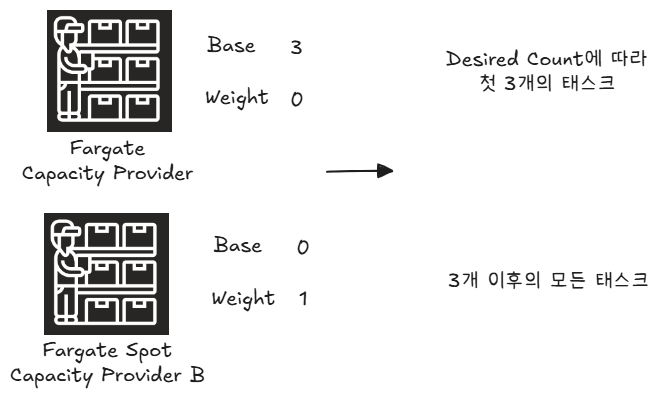
초기의 3개 태스크는 안정적으로 제공되어야 하기 때문에 Fargate를 사용하고, 이후의 버스트 발생 여부에 따라 잠깐 발생할 수 있는 태스크는 Fargate Spot을 이용해 비용을 절약하게끔 base와 weight를 조절한 예시이다. 이렇듯, 여러 Capacity Provider를 사용하더라도 예상 가능한 행동으로 이어지게끔 사용하는 것이 좋다고 생각한다.
'DevOps > AWS' 카테고리의 다른 글
| AWS - ECS EC2 유형의 네트워크 모드 및 비용 (2) | 2025.05.01 |
|---|---|
| AWS - Elastic Container Service(ECS) 구성과 Fargate (0) | 2025.04.14 |
| AWS - Elastic Container Registry(ECR) (0) | 2025.04.08 |
| AWS - Auto Scaling Group(ASG) (0) | 2025.03.08 |
| AWS - Elastic Load Balancer(ELB) & Elastic Beanstalk(EB) (0) | 2024.11.03 |